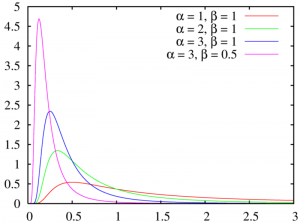
In probability theory, the inverse Gaussian distribution (also known as the Wald distribution) is a two-parameter family of continuous probability distributions with support on (0,∞).
Its probability density function is given by
for x > 0, where is the mean and is the shape parameter.
The inverse Gaussian distribution has several properties analogous to a Gaussian distribution. The name can be misleading: it is an inverse only in that, while the Gaussian describes a Brownian motion's level at a fixed time, the inverse Gaussian describes the distribution of the time a Brownian motion with positive drift takes to reach a fixed positive level.
Its cumulant generating function (logarithm of the characteristic function) is the inverse of the cumulant generating function of a Gaussian random variable.
To indicate that a random variable X is inverse Gaussian-distributed with mean μ and shape parameter λ we write .
Properties
Single parameter form
The probability density function (pdf) of the inverse Gaussian distribution has a single parameter form given by
In this form, the mean and variance of the distribution are equal,
Also, the cumulative distribution function (cdf) of the single parameter inverse Gaussian distribution is related to the standard normal distribution by
where , and the is the cdf of standard normal distribution. The variables and are related to each other by the identity
In the single parameter form, the MGF simplifies to
An inverse Gaussian distribution in double parameter form can be transformed into a single parameter form by appropriate scaling where
The above paragraph can be re-written as: if , then . This approach is better in the sense that it clearly shows dimensionless nature of the single parameter form (note that ). This property follows from a more general fact: if and , then .
The standard form of inverse Gaussian distribution is
Summation
If Xi has an distribution for i = 1, 2, ..., n
and all Xi are independent, then
Note that
is constant for all i. This is a necessary condition for the summation. Otherwise S would not be Inverse Gaussian distributed.
Scaling
For any t > 0 it holds that
Exponential family
The inverse Gaussian distribution is a two-parameter exponential family with natural parameters −λ/(2μ2) and −λ/2, and natural statistics X and 1/X.
For fixed, it is also a single-parameter natural exponential family distribution where the base distribution has density
Indeed, with ,
is a density over the reals. Evaluating the integral, we get
Substituting makes the above expression equal to .
Relationship with Brownian motion
Let the stochastic process Xt be given by
where Wt is a standard Brownian motion. That is, Xt is a Brownian motion with drift .
Then the first passage time for a fixed level by Xt is distributed according to an inverse-Gaussian:
i.e
(cf. Schrödinger equation 19, Smoluchowski, equation 8, and Folks, equation 1).
When drift is zero
A common special case of the above arises when the Brownian motion has no drift. In that case, parameter μ tends to infinity, and the first passage time for fixed level α has probability density function
(see also Bachelier: 74 : 39 ). This is a Lévy distribution with parameters and .
Maximum likelihood
The model where
with all wi known, (μ, λ) unknown and all Xi independent has the following likelihood function
Solving the likelihood equation yields the following maximum likelihood estimates
and are independent and
Sampling from an inverse-Gaussian distribution
The following algorithm may be used.
Generate a random variate from a normal distribution with mean 0 and standard deviation equal 1
Square the value
and use the relation
Generate another random variate, this time sampled from a uniform distribution between 0 and 1
If
then return
else return
Sample code in Java:
And to plot Wald distribution in Python using matplotlib and NumPy:
Related distributions
- If , then for any number
- If then
- If for then
- If then
- If , then .
The convolution of an inverse Gaussian distribution (a Wald distribution) and an exponential (an ex-Wald distribution) is used as a model for response times in psychology, with visual search as one example.
History
This distribution appears to have been first derived in 1900 by Louis Bachelier as the time a stock reaches a certain price for the first time. In 1915 it was used independently by Erwin Schrödinger and Marian v. Smoluchowski as the time to first passage of a Brownian motion. In the field of reproduction modeling it is known as the Hadwiger function, after Hugo Hadwiger who described it in 1940. Abraham Wald re-derived this distribution in 1944 as the limiting form of a sample in a sequential probability ratio test. The name inverse Gaussian was proposed by Maurice Tweedie in 1945. Tweedie investigated this distribution in 1956 and 1957 and established some of its statistical properties. The distribution was extensively reviewed by Folks and Chhikara in 1978.
Rated Inverse Gaussian Distribution
Assuming that the time intervals between occurrences of a random phenomenon follow an inverse Gaussian distribution, the probability distribution for the number of occurrences of this event within a specified time window is referred to as rated inverse Gaussian. While, first and second moment of this distribution are calculated, the derivation of the moment generating function remains an open problem.
Numeric computation and software
Despite the simple formula for the probability density function, numerical probability calculations for the inverse Gaussian distribution nevertheless require special care to achieve full machine accuracy in floating point arithmetic for all parameter values. Functions for the inverse Gaussian distribution are provided for the R programming language by several packages including rmutil, SuppDists, STAR, invGauss, LaplacesDemon, and statmod.
See also
- Generalized inverse Gaussian distribution
- Tweedie distributions—The inverse Gaussian distribution is a member of the family of Tweedie exponential dispersion models
- Stopping time
References
Further reading
- Høyland, Arnljot; Rausand, Marvin (1994). System Reliability Theory. New York: Wiley. ISBN 978-0-471-59397-3.
- Seshadri, V. (1993). The Inverse Gaussian Distribution. Oxford University Press. ISBN 978-0-19-852243-0.
External links
- Inverse Gaussian Distribution in Wolfram website.